A gentle introduction
This page gives a high-level overview. It explains Arbitrum, its purpose, and a brief "how it works." As you progress through the articles in this section, the content will get more technical and dive deeper into each component(s) and function(s) of the Arbitrum technology stack.
Arbitrum is a technology suite designed to improve Ethereum. You can use Arbitrum chains for the same things you do on Ethereum, like using Web3 apps and deploying smart contracts. The difference is that your transactions will be cheaper and faster. Our main product, Arbitrum Rollup, is an Optimistic Rollup protocol that offers the same security as Ethereum.
But why?
Ethereum is awesome, but it has its limitations. The Ethereum Blockchain can handle only about 20 to 40 transactions per second (TPS) for all users. Once it reaches this limit, users must compete for space to have their transactions included, increasing fees.
Arbitrum Rollup solves this issue! Here's how it works: an Arbitrum Rollup Chain acts as a submodule within Ethereum. Unlike regular Ethereum transactions, we don't need Ethereum nodes to handle every Arbitrum transaction. Instead, Ethereum takes an "innocent until proven guilty" stance with Arbitrum. Initially, the Parent chain assumes that actions on Arbitrum follow the rules. If there is a rule violation (like someone claiming, "Now I have all of your money"), that claim is challengeable on the parent chain. In this case, we can prove fraud, disregard the invalid claim, and penalize the guilty party. This ability to investigate and confirm fraud on the parent chain is Arbitrum's main feature and explains why it benefits from Ethereum's security.
How do these fraud proofs work?
People who help manage the Arbitrum chain on the parent chain are called validators. They make claims about the chain's state, dispute others' claims, and more. Most Arbitrum users are unlikely to run a validator, just as most Ethereum users do not operate their parent chain staking node. However, anyone can become a validator; you don't need special permission (once the allowlist gets lifted). You only need to run the open source validator software and bond ETH if required.
The chain stays secure if there is at least one honest validator. It only takes one trustworthy fraud prover to catch many bad actors. These features make the system "Trustless." Users do not depend on any specific group to keep their funds safe.
Who does this fraud proofing?
This step is where the "Rollup" part comes in. Arbitrum Rollup chains handle user transaction data by posting it directly on Ethereum. This setup means that as long as Ethereum is secure, anyone can see what happens on Arbitrum. They can also spot and prove any fraud that occurs.
Validators are the nodes that help move the Arbitrum Chain state forward on the parent chain. They make claims about the chain's state and can dispute claims made by others. Most Arbitrum users are unlikely to want to run a validator, just as most Ethereum users typically don't run their parent chain staking nodes. However, anyone can become a validator. Once the allowlist gets removed, users only need to run the open-source validator software and bond ETH if they need to take action.
The network stays secure if there is at least one honest validator, which means that just one trustworthy fraud prover can catch any number of bad actors. This setup makes the system "trustless"; users do not have to rely on any specific person to keep their funds safe.
The game
It's not as complicated as it seems. If two validators disagree, only one is telling the truth. In the event of a dispute, the two validators engage in an interactive game, where they respond to each other in a call-and-response format. This process allows them to narrow their disagreement to a single computational step—something straightforward, like multiplying two numbers. This step executes on the parent chain, which shows which party is honest. For a more detailed explanation, see here.
Users only experience delays when they withdraw funds from Arbitrum back to Ethereum. When withdrawing directly from Arbitrum to Ethereum, users usually wait one week to receive their funds on the parent chain. However, users can skip this waiting period if they use a fast bridge application, often for a small fee. Other activities do not have this delay, like depositing funds from Ethereum to Arbitrum or using a decentralized application (dApp) on the Arbitrum chain.
How is it cheaper?
Arbitrum helps lower user transaction costs by reducing the strain on the parent chain. The primary way it does this is by processing transactions in batches. A batch can contain several hundred child chain transactions and gets submitted as one parent chain transaction. This batching makes interacting with the parent chain cheaper since you save on overhead costs compared to submitting each transaction individually.
Additionally, Arbitrum posts transaction data on the parent chain in a compressed format. It only decompresses this data within the child chain environment, reducing the amount of information that needs storing on the parent chain.
How does it all work together?
At the most basic level, an Arbitrum chain works like this:
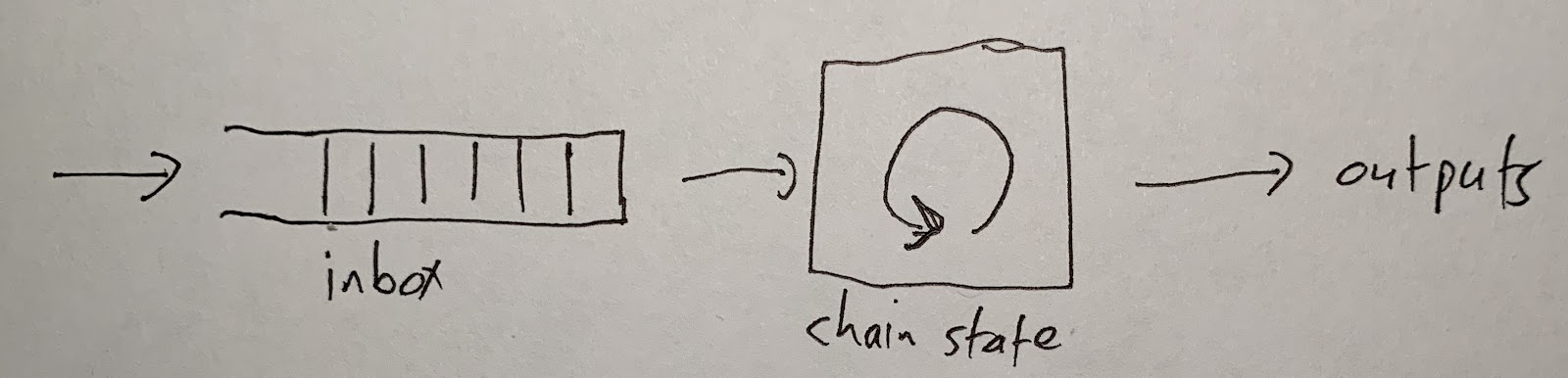
Users and contracts put messages into the inbox. The chain reads the messages one at a time and processes each one. This processing updates the state of the chain and produces some outputs.
If you want an Arbitrum chain to process a transaction for you, you need to put that transaction into the chain's inbox. Then, the chain will see your transaction, execute it, and produce some outputs: a transaction receipt and any withdrawals that your transaction initiated.
Execution is deterministic, meaning that the contents of its inbox uniquely determine the chain's behavior. Because of this, the result of your transaction is knowable as soon as it gets put in the inbox. Any Arbitrum node will be able to tell you the result. (And you can run an Arbitrum node yourself if you want.)
All of the technical details in this document connect to this diagram. To get from this diagram to a complete description of Arbitrum, we'll need to answer questions like these:
- Who keeps track of the inbox, Chain state, and outputs?
- How does Arbitrum make sure that the chain state and outputs are correct?
- How can Ethereum users and contracts interact with Arbitrum?
- How does Arbitrum support Ethereum-compatible contracts and transactions?
- How are ETH and tokens transferred into and out of Arbitrum chains, and how are they managed while on the chain?
- How can I run my own Arbitrum node or validator?
Nitro's Design: The Four Big Ideas
The essence of Nitro and its key innovations lie in four big ideas. We'll list them here with a quick summary of each. We will unpack them in more detail in later sections.
Big Idea: Sequencing, Followed by Deterministic Execution: Nitro processes transactions with a two-phase strategy. First, the transactions get organized into a single-ordered sequence, and Nitro commits to that sequence. Then, the transactions get processed in that sequence by a deterministic State Transition Function.
Big Idea: Geth at the Core: Nitro supports Ethereum's data structures, formats, and virtual machine by compiling in the core code of the popular go-ethereum ("Geth") Ethereum node software. Using Geth as a library in this way ensures a very high degree of compatibility with Ethereum.
Big Idea: Separate Execution from Proving: Nitro takes the same source code and compiles it twice, once to native code for execution in a Nitro node, optimized for speed, and again to WASM for use in proving, optimized for portability and security.
Big Idea: Optimistic Rollup with Interactive Fraud Proofs: Nitro settles transactions to the parent Ethereum chain using an Optimistic Rollup protocol, including the interactive fraud proofs pioneered by Arbitrum. Now that we have covered the foundational concepts, the big picture, and the four big ideas of Arbitrum Nitro, we will begin a journey following a transaction through the Arbitrum protocol. In the next section, the transaction lifecycle begins.