Inside Arbitrum Nitro
Transaction processing journey on Arbitrum
As a developer initiating a transaction on Arbitrum, gaining a clear understanding of the end-to-end flow—from initial submission through to finality—is helpful, but it isn't required.
This overview methodically traces the transaction lifecycle, emphasizing how Arbitrum’s architecture ensures precise, efficient, and secure handling at every stage. This article covers the complete Arbitrum Nitro stack, beginning with the Sequencer, which is responsible for transaction ordering, advancing to the State Transition Function (STF) for execution, and culminating in validation mechanisms that uphold integrity.
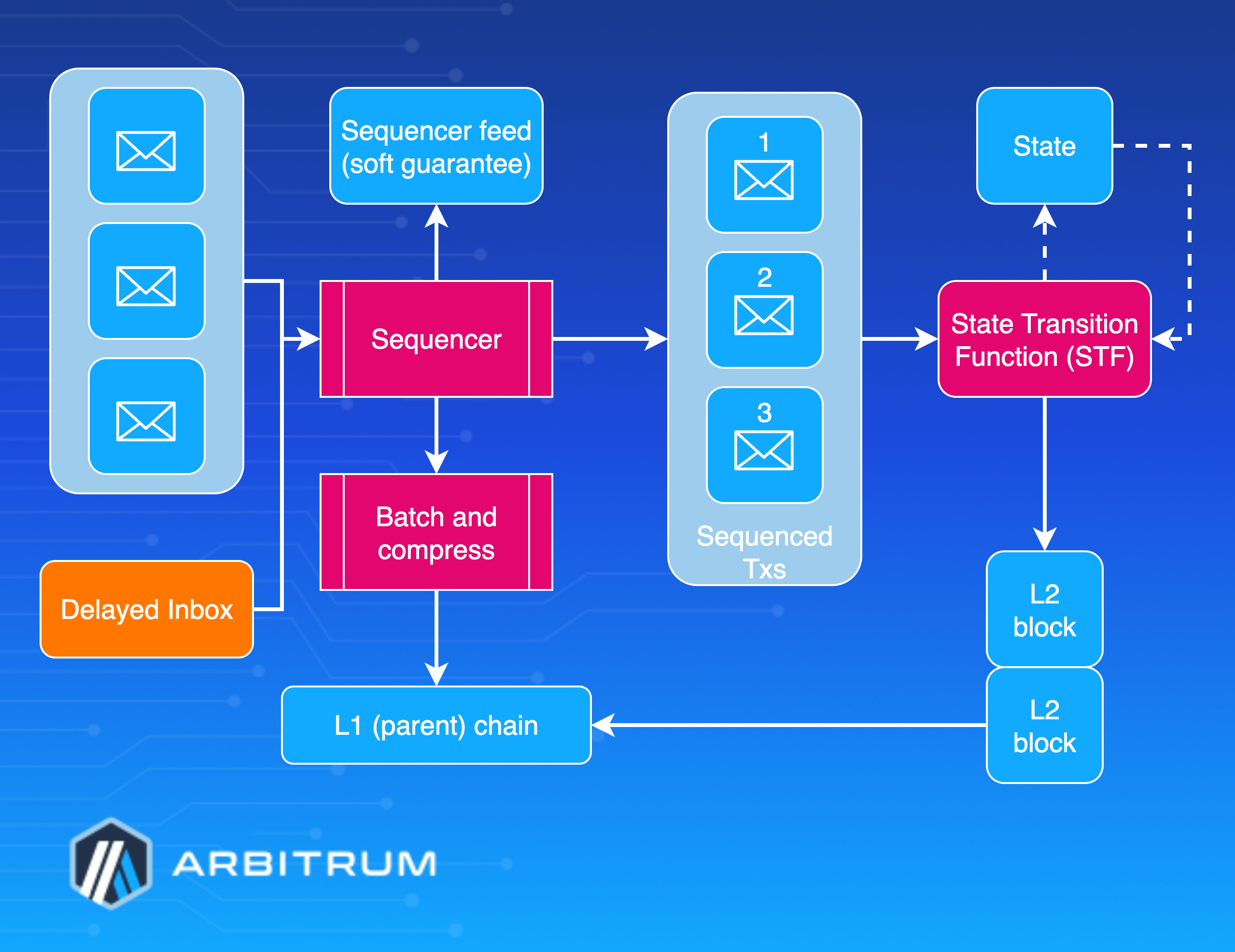
Transaction lifecycle
Along the way, you'll learn about Arbitrum's ability to deliver security on par with Ethereum, while achieving fee reductions by a factor of ten and transaction speeds accelerated by a factor of 100 using optimized mechanisms.
The foundation: Arbitrum's core architecture overview
Before delving into the journey of a transaction, it's important to outline the foundational architecture that powers Arbitrum's operations. Central to the architecture is a simple yet powerful principle: deterministic state transitions, which ensure consistent outcomes across the network. The system revolves around three core components:
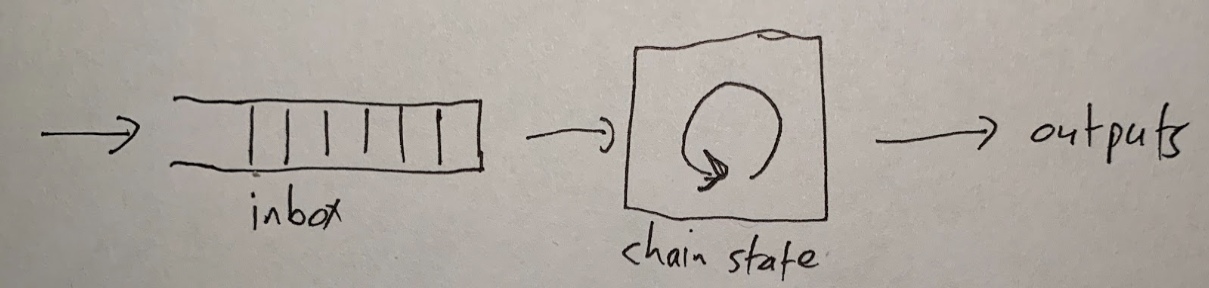
Transactions first enter the Inbox, serving as the primary gateway into the ecosystem. From there, the STF processes them deterministically, applying rules that guarantee reproducibility. Finally, the Outputs component generates the resulting data and state updates, completing the cycle.
The deterministic model ensures that identical inputs will always produce the same outputs, among honest nodes, forming the bedrock of Arbitrum’s security. It supports efficient fraud proofs and dispute resolution, enabling verification of execution correctness without re-running entire transactions, thereby minimizing computational overhead.
For foundational concepts about the STF, see the State Transition Function gentle introduction.
Step 1: Submitting a transaction
The submission process for a transaction on Arbitrum starts with the user sending the request, with options tailored to balance factors such as speed, control, and reliability based on specific needs. Most transactions route through the Sequencer, a specialized node that orders transactions and issues quick confirmations.
This path accommodates various submission methods, including public RPC for development and light usage, third-party RPCs for improved throughput, direct Sequencer endpoints for minimal latency in critical operations, and self-hosted Arbitrum nodes for ultimate privacy and customization.
Alternatively, to mitigate the risks of exclusion or delays by the Sequencer, users can submit directly to the Delayed Inbox contract on Ethereum, thereby bolstering system resilience. In this mechanism, non-Sequencer transactions enter a dedicated queue, where a well-functioning Sequencer typically integrates them within about ten minutes. If delayed for more than 24 hours, any network participant can force inclusion into the main inbox, limiting the Sequencer's ability to block transactions permanently—it can only add a temporary delay.
While the Sequencer route offers faster soft finality and streamlines workflows, the Delayed Inbox path doubles processing time but emphasizes censorship resistance (blocking transactions). Overall, the Sequencer’s commitment to ordered inclusion provides “soft finality” for a responsive experience, complemented by these alternatives for robust, flexible operations across applications.
For more technical detail about the transaction lifecycle, refer to the Transaction Lifecycle deep dive.
Step 2: Ordering and broadcasting: the Sequencer
Once a transaction reaches the Sequencer, it integrates into a refined system for ordering and broadcasting, designed to maximize performance while upholding security. The Sequencer immediately shares the transaction through its real-time feed, offering instant network-wide visibility.
This feed delivers immediate confirmation of acceptance and sequencing, keeping all nodes synchronized with the latest order and enabling soft finality, allowing users to proceed with confidence based on the Sequencer’s reliable commitment.
To further optimize, the sequencer groups transactions into batches rather than processing them individually, reducing costs and boosting efficiency. Batches form when transactions accumulate to a predefined size or after a set time interval to prevent lags. The data is then compressed using the Brotli algorithm, with the compression level dynamically adjusted from 0 to 11 based on congestion. Higher compression reduces Layer 1 posting expenses at the cost of increased computation, while the system prioritizes speed during heavy backlogs.
After batches and compression, the data posts to Ethereum through the Sequencer Inbox contract using one of two methods:
-
The default blob transactions under EIP-4844 provide cost-effective and scalable data inclusion when supported by Ethereum.
-
As a fallback, calldata transactions embed data directly, ensuring compatibility even if blob fees rise or EIP-4844 blobs are unavailable. This process yields 10-100 times the cost savings over individual postings and adapts to network conditions for consistent efficiency.
For a deeper look at how the Sequencer orders, batches, and posts transactions, see the Sequencer deep dive. For details on how parent chain costs are calculated and priced, including the adaptive pricing algorithm, see the Gas and fees deep dive.
Step 3: Execution phase: State Transition Function
With ordering and batching complete, execution shifts to the State Transition Function (STF), the core of Arbitrum's processing engine.
For foundational concepts about how the STF works, see the State Transition Function gentle introduction.
Arbitrum ensures full Ethereum Virtual Machine (EVM) compatibility via a three-layer architecture. At the base, the Geth core handles EVM execution, aligning behaviors with Ethereum and drawing on its extensively tested code for security.
For more technical details about Geth, refer to the Geth deep dive.
Above this, ArbOS—the Arbitrum operating system—adds child chain features such as cross-chain messaging, fee management, gas pricing, deposit and withdrawal handling, and advanced tooling, such as Stylus. The top layer, the node interface, manages RPC connections and APIs, providing Ethereum-like functionality for clients.
In the STF, transactions follow a structured workflow: first, ArbOS validates formatting and funds, then charges gas for Layer 2 execution and Layer 1 posting. Then Geth executes per EVM standards. Finally, ArbOS updates state and cross-chain elements, generating receipts and logs to finalize the process.
For technical details about ArbOS, refer to the ArbOS deep dive documentation and the ArbOS technical reference.

For Stylus contracts that use WebAssembly (WASM), execution is diverted to a WASM runtime, where contracts access state via specialized host I/O calls. This diversion yields 10-70 times faster performance than EVM equivalents and full interoperability for mixed calls. The Geth base lets Ethereum apps run unchanged, while ArbOS and Stylus enable Layer 2 optimizations and high-performance innovations.
Consult the State Transition Function deep dive for further mechanics.
Step 4: Finality
At this stage, the transaction achieves two complementary levels of finality, each tailored to Arbitrum’s security needs:
-
Soft finality emerges immediately upon inclusion in the Sequencer Feed, offering instant acceptance feedback, a commitment to order, and the ability to act without wait times—as noted in the submission phase. This "soft finality" relies on the Sequencer's trustworthiness for usability but lacks cryptographic backing.
-
Hard finality, conversely, solidifies when the batch is posted and is confirmed on Ethereum, inheriting its consensus security, ensuring public data availability, and making the transaction irreversible. This process typically takes 10-20 minutes, which varies depending on Ethereum’s block times and batch frequency. Hard finality depends on Rollup assertions being confirmed on Ethereum.
The dual model combines quick "soft finality" for a better user experience with Ethereum-level safeguards for hard finality, along with censorship-resistant paths for assured inclusion. This balance delivers immediate feedback alongside strong protections, which is ideal for high-stakes transactions.
For more on how assertions work, see the Assertions deep dive page.
Step 5: Validation and dispute resolution
Following execution, Arbitrum verifies correctness through its validation and dispute systems. Central to this is the BoLD (Bounded Liquidity Delay) protocol, which is an advanced dispute framework that enables permissionless validation. Unlike conventional optimistic Rollups, BoLD permits any participant to validate without approval, while ensuring dispute resolution within bounded timeframes to prevent indefinite delays.
BoLD facilitates a Challenge-based defense where honest parties can protect the chain's state against malicious actors. The individual who raises the dispute and the validator will narrow the conflict to a single execution step via supporting claims, which culminate in a one-step proof (OSP) that Ethereum, as an impartial arbiter, verifies to determine the outcome. While BoLD's intricacies—such as its multi-round challenge games and economic incentives—are extensive, they enhance the chain's decentralization and resilience. Validation occurs through assertions submitted to the Rollup contract.
BoLD references
- For details on how assertions structure validation and disputes, see the Assertions deep dive.
- For an introduction to BoLD, see the BoLD gentle introduction.
- For technical implementation details, see the BoLD technical deep dive.
- For how the bisection protocol narrows disputes to a single step, see How BoLD bisection works.
- For economic considerations, see the Economics of disputes documentation.
Step 6: Bridging—Cross-chain communication
Many transactions involve asset or data transfers between Ethereum and Arbitrum, which are managed through secure bridging protocols (see the Token bridging deep dive for the architecture overview). For parent-to-child transfers from Ethereum to Arbitrum, options include native token bridging for direct ETH deposits, ERC-20 transfers via the canonical bridge, or support for custom gas tokens.
Retryable tickets enable atomic operations with guaranteed retries if execution fails, featuring predictable gas costs and a one-week validity period redeemable by anyone. Direct messaging handles signed EOA messages with verification or unsigned contract messages using address aliasing for security.
See the Parent-to-child messaging deep dive for details.
Child-to-parent transfers from Arbitrum to Ethereum begin with creating a message via ArbSys.sendTxToL1(), followed by inclusion in a Rollup Assertion, a 6.4-day challenge period, and manual Layer 1 execution by any party (see withdrawing tokens for a hands-on guide). Messages are validated via Merkle proofs, persist indefinitely until executed, and require manual triggering due to Ethereum's constraints.
For details on how Rollup assertions work and their role in finality, see the Assertions deep dive.
See the Child-to-parent messaging deep dive documentation for more details on how cross-chain messages work.
The canonical bridge architecture comprises asset contracts on both chains, gateway pairs for specific logic, and routers to direct traffic flow. It securely locks tokens on one chain while minting equivalents on the other, with a seven-day challenge period to safeguard withdrawals. This setup fosters unified interactions while safeguarding the integrity of each chain.
Step 7: The economics of execution: gas and fees
Fees
Fees accumulate throughout the transaction lifecycle to fund processing (computation) and security. Arbitrum’s dual-fee model separates child chain gas fees, which cover the cost of EVM computation and storage with EIP-1559-style dynamic pricing that adjusts for congestion, from parent chain data fees (blobs or calldata).
Parent chain data fees account for posting data to Ethereum in compressed batches and apply only to Sequencer submissions. For a complete breakdown of how fees are calculated and collected, including the dynamic pricing algorithm and both parent and child chain components, refer to the Gas and fees deep dive.
Gas
A gas target is an optimal gas consumption rate per second. Exceeding this rate triggers EIP-1559 fee escalations to prevent node overloads and maintain chain activity. This rate prioritizes high-value transactions during peak periods while deterring spam, ensuring that validators and the Sequencer remain operational, even though parent contracts handle security.
You can read more about how the child chain gas fees are calculated in the gas and fees deep dive.
Fee calculation during execution involves assessing child-chain gas using EVM standards, estimating the parent-chain batch impact, applying current pricing, and collecting ETH totals. This model effectively covers all costs, with the gas target reinforcing security by keeping validation in sync. For practical gas estimation in decentralized apps, see How to estimate gas.
Step 8: Advanced features
Stylus
Arbitrum extends beyond standard Layer 2 capabilities with features like Stylus, which supports smart contracts written in languages such as Rust, C, and C++ via WASM. It offers 10-70 times faster execution and 100-500 times better memory efficiency than the EVM, with full cross-call interoperability. Stylus runs in the co-located WASM VM using host I/O for state access.
For more details, refer to the Stylus gentle introduction page, or jump into the Stylus quickstart to build a contract.
Timeboost
Timeboost refines ordering to capture MEV (maximum extractable value) for chain operators, protects users from attacks such as front-running, reduces spam-related congestion, and enables customizable policies. Timeboost preserves fast block times (250ms default).
Timeboost references
- For an introduction to Timeboost, see the Timeboost gentle introduction.
- For implementation details and usage instructions, see the How to use Timeboost documentation.
- For troubleshooting guidance, see the Timeboost troubleshooting and FAQ pages.
AnyTrust
AnyTrust enables cost-optimized data availability with a mild trust model that relies on a Data Availability Committee (DAC) of N members, where at least two are assumed honest. It uses BLS-signed Data Availability Certificates (DACerts) and falls back to Layer 1 posting if needed.
Keysets define member keys and thresholds; DACerts include hashes, expirations, and signatures; and servers support various storage, such as local files or Amazon S3. The Sequencer sends batches to the committee, gathers signatures for DACerts, and posts them to Layer 1, defaulting to full data if the required signatures are not present. Ideal for low-cost apps like gaming.
For a more complete understanding of AnyTrust, refer to the AnyTrust protocol documentation. For the operator-side view of running a DAS, see the data availability node guide.
Related topics
In this overview, you've learned about the complete transaction journey through Arbitrum Nitro. For a deeper exploration of specific topics, refer to the resources below:
Deep dives
- Transaction Lifecycle: Detailed transaction lifecycle from submission to finality
- Sequencer: How the Sequencer orders, batches, and posts transactions
- Gas and fees: Gas pricing, fee calculations, and adaptive pricing algorithm
- State Transition Function: Gentle Introduction: Foundational concepts of the STF
- Geth: Geth core and EVM compatibility
- ArbOS: Arbitrum Operating System features and capabilities
- State Transition Function inputs: Message types and STF processing mechanics
- Assertions: Rollup assertions and validation structure
- Parent-to-child messaging: L1 to L2 messaging and bridging
- Child-to-parent messaging: L2 to L1 messaging and withdrawals
- Token bridging: Canonical bridge architecture, gateways, and routers
- AnyTrust protocol: Data availability committee and cost optimization
BoLD (Bounded Liquidity Delay)
- BoLD: Gentle introduction: Overview of permissionless validation
- BoLD technical deep dive: Implementation details of the dispute protocol
- How BoLD bisection works: Narrowing disputes to a single execution step
- Economics of disputes: Bonding, incentives, and cost considerations
Timeboost
- Timeboost: Gentle Introduction: MEV capture and transaction ordering